start
Media Manager
Namespaces
Choose namespace


Media Files
Files in guides:user:compliance
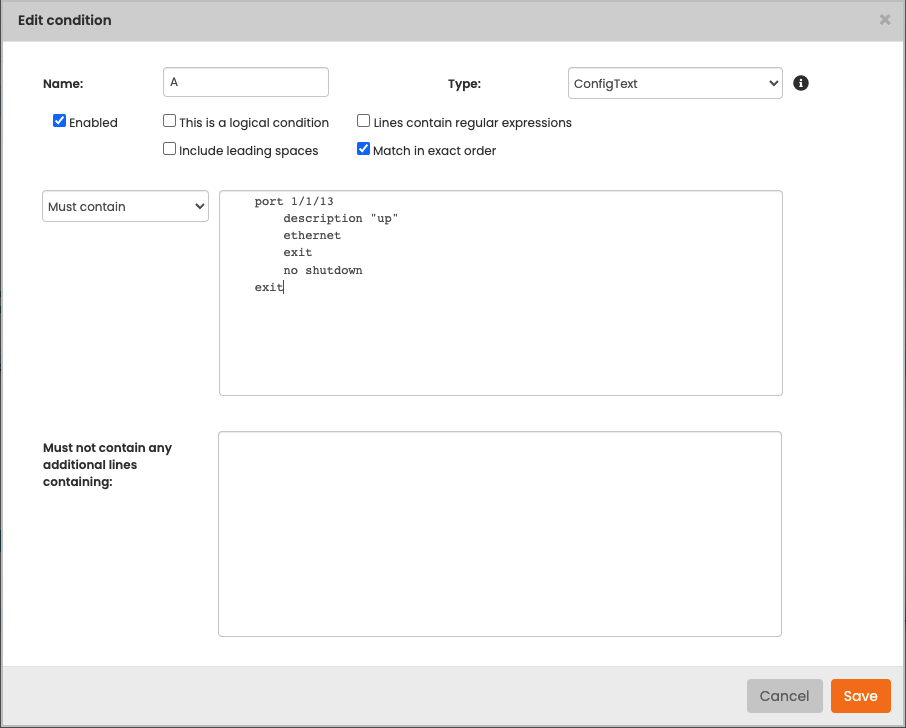
- cmpl_edit_condition.png
- 906×728
- 2024/07/03 12:31
- 45.5 KB
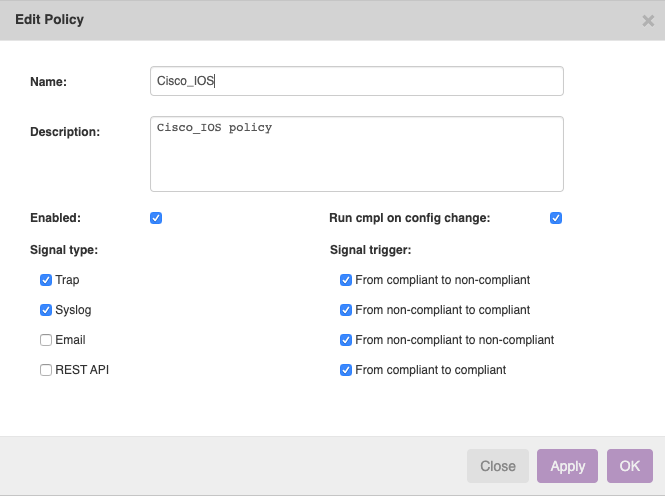
- cmpl_edit_policy.png
- 665×496
- 2024/07/03 12:31
- 38 KB
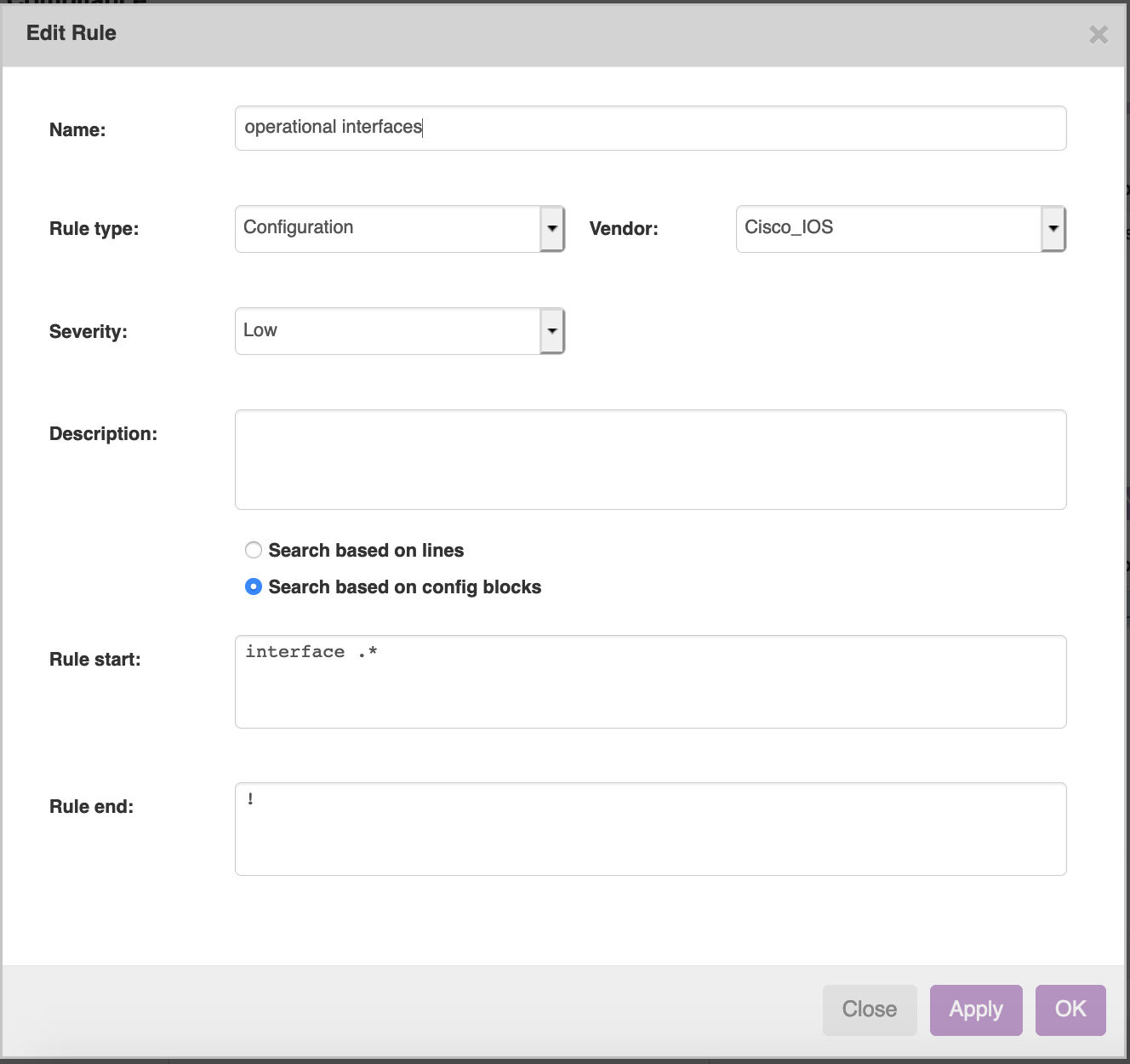
- cmpl_edit_rule.png
- 1328×1250
- 2024/07/03 12:31
- 95.5 KB
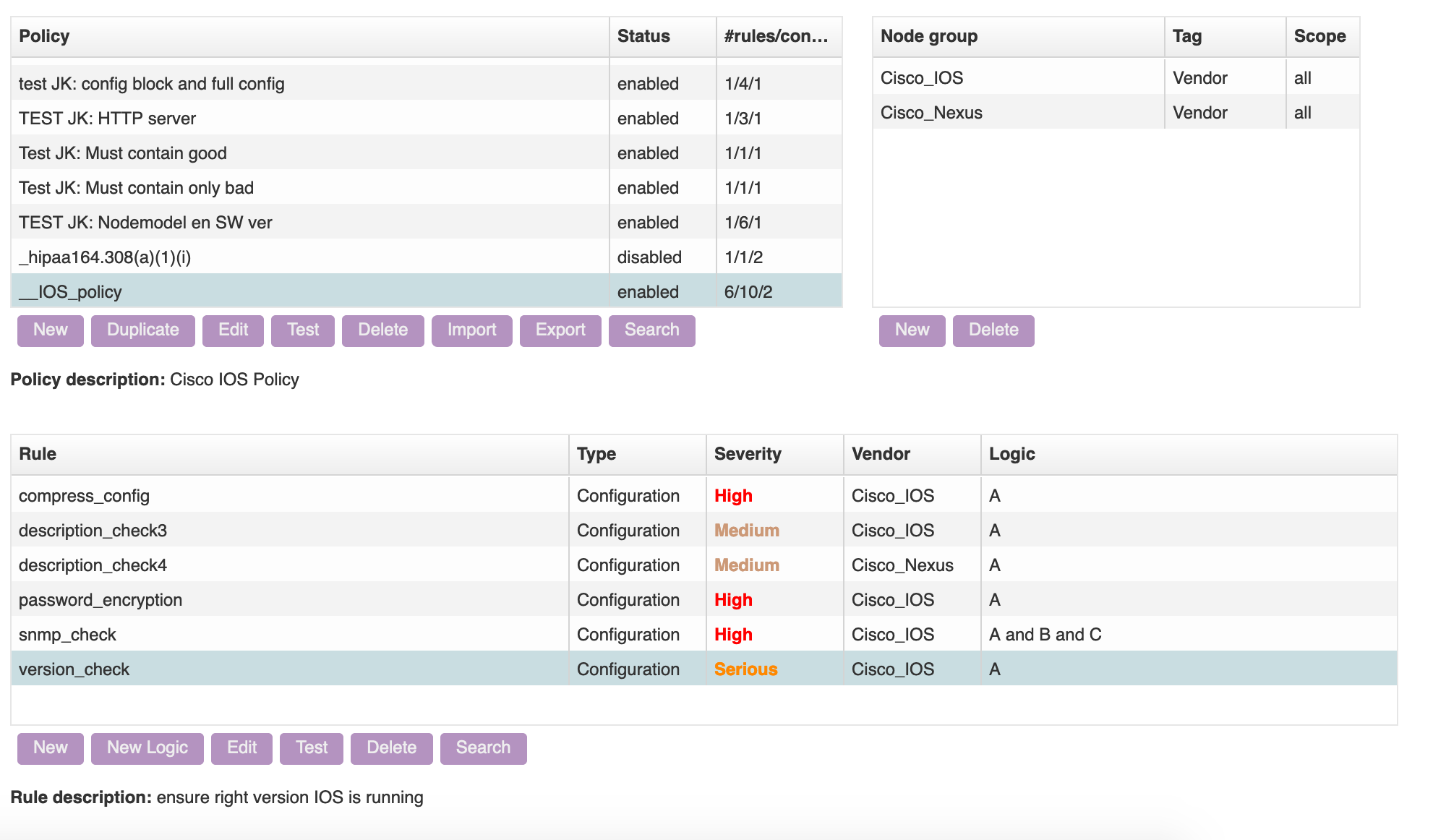
- cmpl_policies.png
- 1982×1162
- 2024/07/03 12:31
- 241 KB
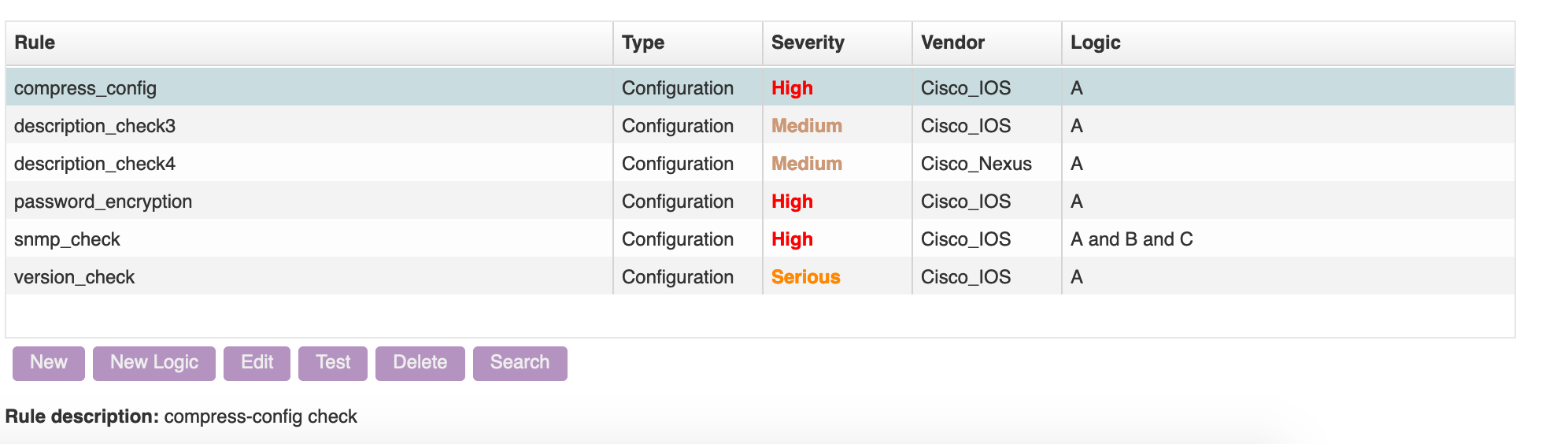
- cmpl_rules_overview.png
- 1992×564
- 2024/07/03 12:31
- 118.7 KB
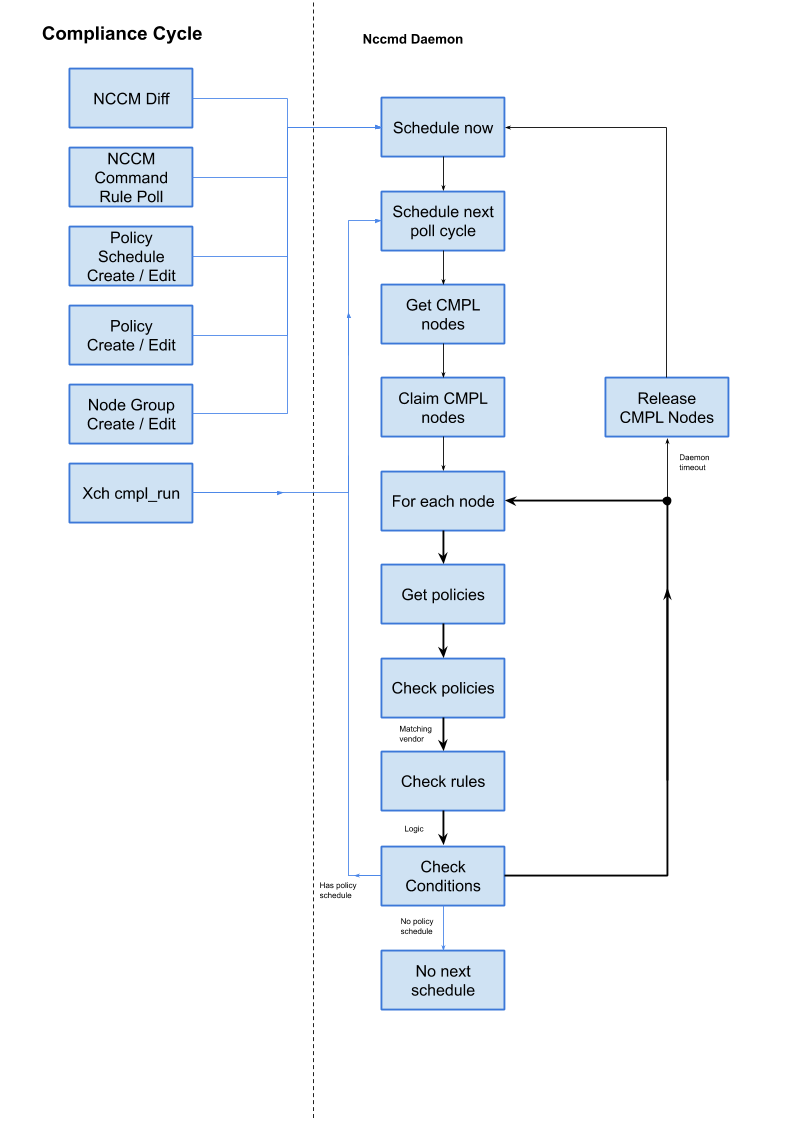
- compliance_cycle.png
- 793×1121
- 2024/07/03 12:31
- 46.3 KB
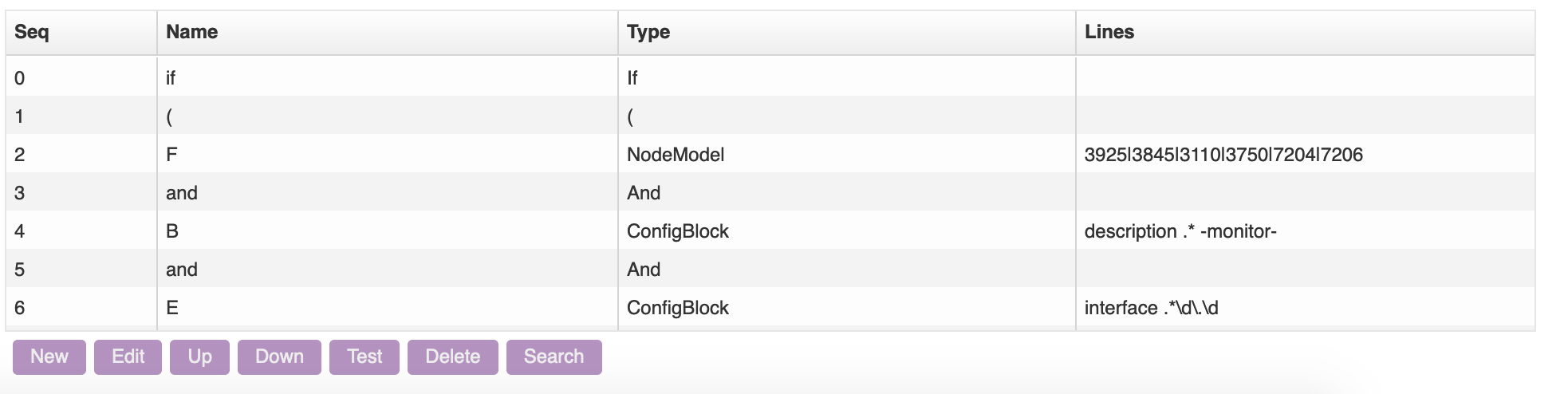
- conditions_grid.png
- 1966×494
- 2024/07/03 12:31
- 75.2 KB
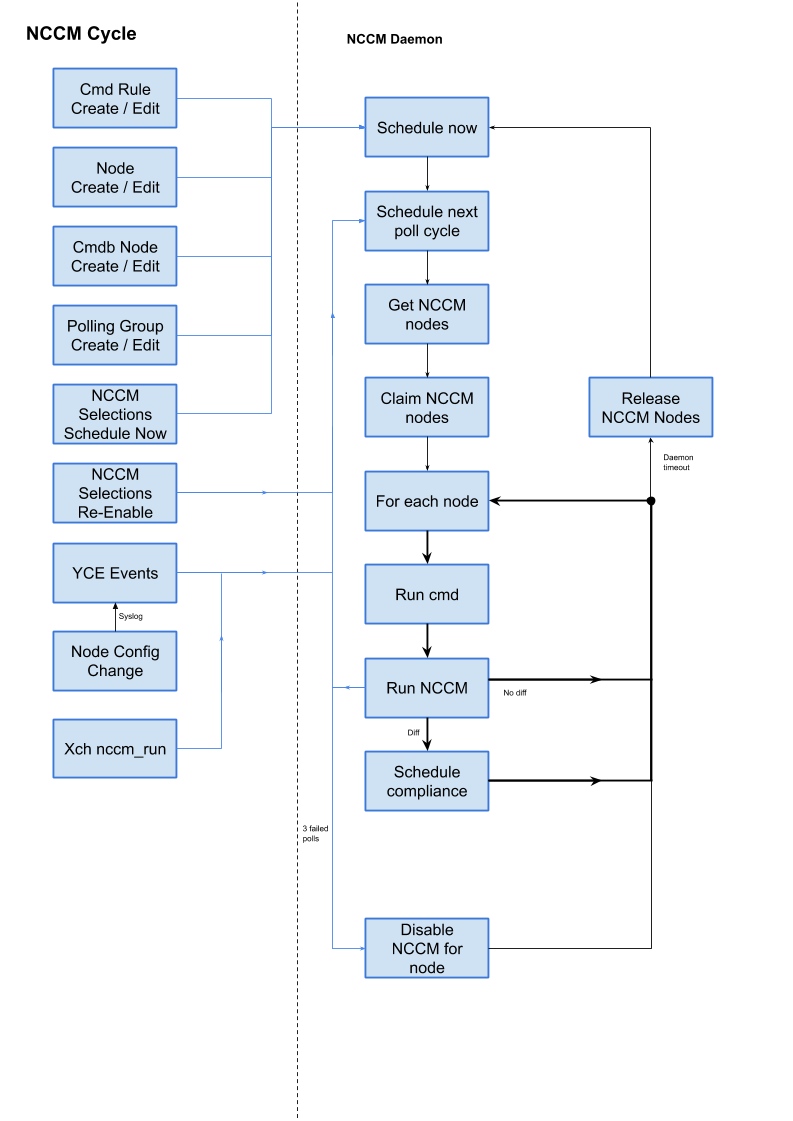
- nccm_cycle.png
- 793×1121
- 2024/07/03 12:31
- 51.5 KB








File
start.txt · Last modified: 2024/09/11 07:44 by admin